
Welcome back. If you missed Part 1, that post was about the difference between vibe coding and a more systematic engineering mindset. [R1]
After rereading my old Part 2 draft, I think I was chasing the wrong angle. It leaned too hard into one specific user group and one local-market story. That is a valid lens for some products, but it is not the real lesson I want to leave behind here. Here is my honest correction: the bigger lesson is how to build project context that survives the next chat, the next agent, and the next week of your own forgetfulness. [R1][R2][R3][R4][R5]
That sounds less sexy than “AI builds production app for market X,” I know. But let’s be real. Most AI-assisted projects do not die because the model was weak. They die because nobody kept the memory of the project in a durable place. The prompt was great for one afternoon. The project was not great for the second session. [R2][R3][R4]

The Question That Changed My Thinking
In the first months of my AI coding journey, I kept trying to solve everything with better prompts. Longer prompts. More detailed prompts. Smarter prompts. And yes, sometimes that helped. But every new session still had the same stupid problem: the agent did not know what happened before, why I made certain choices, what commands were safe, or which unfinished edge cases were already discovered.
That was the moment I stopped asking, “Which tool is better, Kiro or Copilot or Codex?” and started asking a much more useful question: What must exist inside the project folder so any future agent can recover context fast? [R2][R4][R5]
OpenAI now documents that Codex aggregates project instructions from AGENTS.md files in the repo tree and uses them as part of the prompt construction process. Anthropic does something very similar with CLAUDE.md, and Kiro now explicitly supports the AGENTS.md pattern too. So this is not just my private obsession anymore. It is becoming a cross-tool operating pattern. [R2][R4][R5]
The real upgrade was not “better prompting.” It was moving knowledge out of my head and into the repo.
My Beginner-Friendly Project Context Framework
So here is the simplified version I actually use now. Not a giant framework. Not ten documents. Just a project context stack that is small enough for beginners and strong enough to help the next agent session.
| File / layer | What it does | When I update it | Beginner version |
|---|---|---|---|
README.md | Explains what the project is and how to start it. | When the project goal or setup changes. | 5-10 lines is enough. |
AGENTS.md | Stores rules, commands, constraints, naming, and operational guidance. | When I learn “always do X, never do Y” inside this repo. | A few short bullets. |
CHANGELOG.md | Keeps a curated, time-ordered memory of notable changes. | After important fixes, decisions, or new features. | One line per notable change. |
SOP.py or scripts | Turns repeated tasks into executable routines. | When I repeat the same manual flow twice or three times. | Even one command wrapper helps. |
| Short ADR note | Explains why a costly technical decision was made. | Only when reversing the choice would be painful. | A tiny markdown file is enough. |
This stack is basically my answer to the messy-middle reality of AI-assisted building. I still use intuition. I still experiment. But I no longer trust raw chat history as the memory system for the project. [R2][R4][R7][R8]
PlantUML Diagram: Project Context Stack
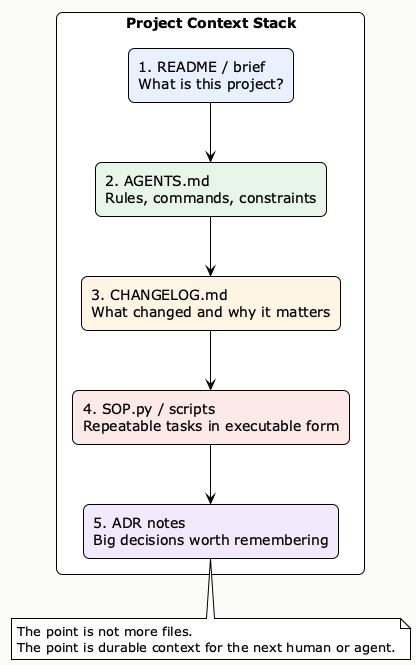
What Each File Is Really For
1. AGENTS.md is the operating manual for the repo
AGENTS.md is where I write the things I do not want to explain again and again: safe commands, dangerous areas, naming rules, where services live, how to run tests, and what not to touch casually. In OpenAI Codex, these repo instructions are explicitly aggregated from the project tree. In Kiro, AGENTS.md is now a supported standard. In Claude Code, the same role is handled by CLAUDE.md. Different file names, same idea: the project should teach the tool how to behave inside this folder. [R2][R4][R5]
What I do not put there: essay-length explanations, old arguments, or every detail of product strategy. If the file gets too large, it stops being useful. Anthropic even recommends staying concise because those instructions consume context and can become contradictory when they sprawl. [R4]
2. CHANGELOG.md is project memory, not git spam
This one matters more than I expected. A good changelog is not a dump of every commit. The Keep a Changelog guidance is simple and still correct: it should be a curated, chronological list of notable changes so people can quickly see what changed between versions. That is exactly what the next agent needs too. [R7]
When I return to a repo after a few days, CHANGELOG.md tells me which bug was already fixed, which workaround is temporary, which refactor was risky, and whether the project is getting healthier or just noisier.
3. SOP.py is where repetitive work stops being a memory problem
This is probably the piece that clicked with me the most. If a task matters and I will repeat it, I do not want the knowledge trapped in prose forever. I want the workflow executable. That is why I like a simple SOP.py or a small scripts folder. It can hold tasks like publishing a draft, syncing assets, seeding demo data, or validating a deployment checklist.
Kiro’s hook model pushed my thinking here as well. Their docs and blog show the same direction: hooks can update tests, synchronize README files, generate changelog help, and apply standards from workspace context. In other words, documentation tells the agent what good looks like; automation helps keep that truth fresh. [R5][R6]
4. ADRs are for the expensive decisions
I do not write ADRs for tiny choices. But when I choose a database, deployment pattern, auth approach, or integration boundary, I want a short note saying why. Google Cloud’s ADR guidance frames this well: ADRs help explain why teams make certain design choices as they build and run applications. That “why” becomes gold later when the code alone is no longer obvious. [R8]
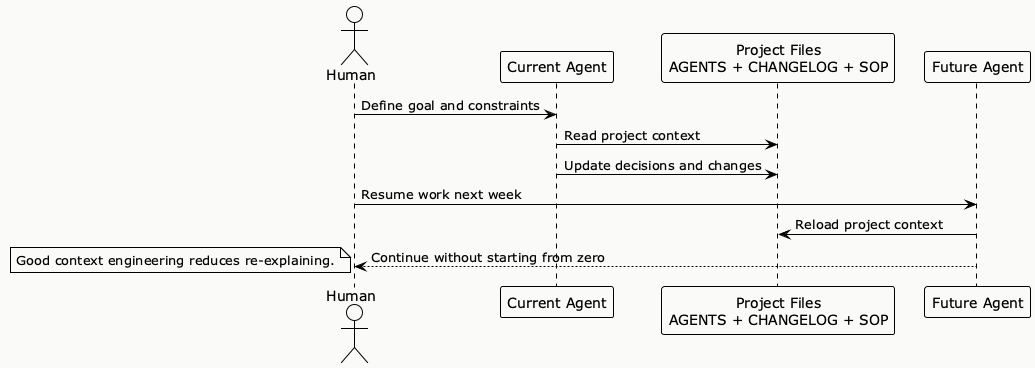
PlantUML Diagram: Human-to-Agent Handoff Loop
Where This Fits in the 2025-2026 Memory Landscape
This is the part I think was missing before. My little repo-level framework is not happening in isolation. In 2025 and 2026, the whole agent world started taking memory and context retention much more seriously. Some people approached it from research papers. Others approached it from product design. And the two worlds are starting to overlap. [R9][R10][R11][R12][R13][R14][R15][R16][R17]
So if you zoom out, there are really two big camps:
- Memory architecture frameworks: these try to solve how an agent stores, promotes, retrieves, and refines memory over time.
- Practical coding-agent patterns: these focus on durable files, instructions, skills, hooks, and scripts that survive the next session inside a real project folder.
My honest take? The research side is getting smarter fast. But for beginners building software projects today, the strongest move is still to start with durable files in the repo and only add more advanced memory systems when the project actually needs them.
| Framework or pattern | Year | How context is retained | Best use case | How it relates to my project-memory stack | Main limitation |
|---|---|---|---|---|---|
| PEM / Place Event Memory | 2025 | What-where-when episodic memory with place and event clusters. | Embodied agents and long-horizon environment tasks. | Useful conceptually because it shows memory is not just text history; it can be structured by event and location. [R11] | Not designed for software repos or everyday coding workflows. |
| Memory OS of AI Agent | 2025 | Three storage tiers: short-term, mid-term, and long-term personal memory, with explicit update and retrieval modules. | Long conversations and personalized assistants. | Very close to how I now think about daily notes, curated memory, and selective retrieval. [R12] | Still more conversation-centric than repo-centric. |
| MemOS | 2025-2026 | Memory-OS model with persistent skill memory and cross-task reuse. | Larger agent platforms that want reusable memory plus reusable skills. | Interesting because it connects memory retention with skill reuse, which feels very aligned with Codex and OpenClaw style workflows. [R13] | Heavier than what most solo builders need on day one. |
| ReMe | 2025 | File-based and vector-based memory with personal, procedural, and tool memory. | Agents that need a modular memory kit without inventing one from scratch. | Probably the cleanest bridge between product memory and practical coding memory. [R14] | Still adds another memory subsystem you need to own and maintain. |
| Codex + AGENTS.md + Skills | 2025-2026 | Repo instructions, reusable skill bundles, and agent-loop context management. | Coding tasks inside a real codebase. | Very high overlap with my stack: instructions, reusable workflows, and task packaging matter more than one giant prompt. [R2][R3][R9][R10] | Great instructions still fail if humans never update the files. |
| Claude Code + project memory | 2025-2026 | CLAUDE.md plus project memory files that are checked into source control. | Long-running coding sessions with shared team context. | Very similar philosophy: keep durable truth in files, not only in chat. [R4] | Can sprawl if the memory files become too large or too stale. |
| Kiro + AGENTS.md + hooks | 2025-2026 | Instruction files plus hooks that can keep docs, tests, and context synchronized automatically. | Teams who want context plus enforcement. | This is where my SOP.py thinking got stronger: memory is better when some of it becomes executable. [R5][R6] | Hooks add power, but also operational complexity. |
| OpenClaw + MEMORY.md + daily logs + skills + hooks | 2026 | Markdown source-of-truth files, searchable memory index, skill precedence, hook-driven writeback, and pre-compaction memory flush. | Self-hosted, multi-agent, long-running workflows. | This is the closest practical system I have seen to “project memory as an operating layer.” It combines files, skills, retrieval, and automatic writeback. [R15][R16][R17] | It is powerful, but you own more moving parts. |
So the pattern I see is this: research frameworks are trying to improve memory architecture, while product tools are standardizing durable context artifacts. One is asking, “How should memory be organized?” The other is asking, “What must survive in the project folder so work can continue tomorrow?”
PlantUML Diagram: How modern coding agents pull context from multiple layers
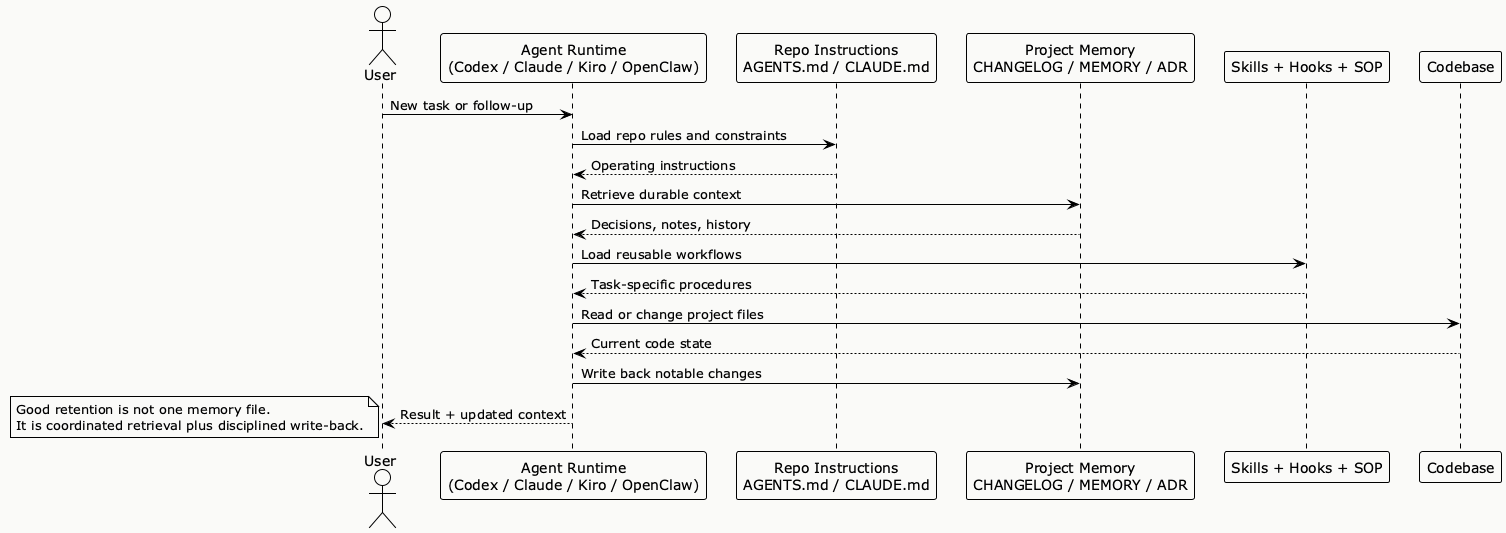
PlantUML Diagram: From active context to durable memory
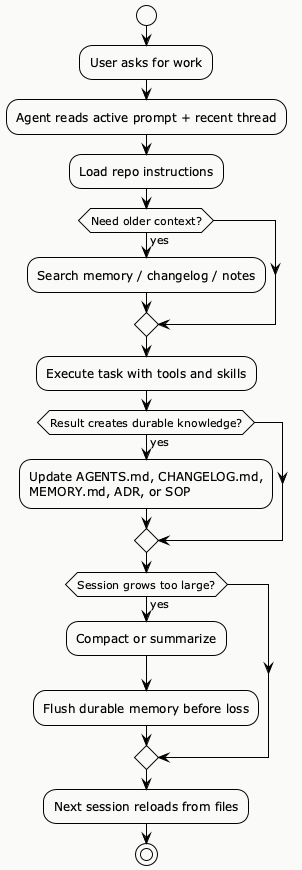
If I compress all of this into one practical lesson, it would be this: the current state of context retention is converging toward layered memory. Active context handles the current turn. Durable files handle project truth. Skills and hooks handle repeatability. Smarter memory frameworks sit on top when you need more selective retrieval or longer-term adaptation. [R10][R12][R13][R14][R15][R16][R17]
And that is exactly why I still trust the beginner stack I described earlier. It is boring, but it composes well with everything else. If one day you add vector memory, a memory OS, or more advanced retrieval, the repo files still remain the safest ground truth.
The Failure Cost When These Files Do Not Exist
Wait, let me back up a bit. Why am I so stubborn about this now? Because I already paid the cost of not doing it. Not in money only, but in rework, confusion, and fake progress. Here is the small failure ledger from my own learning pattern:
| Missing context piece | What happened | Cost |
|---|---|---|
| No repo instructions | New agent starts with generic assumptions. | Wrong edits, wasted prompts, avoidable risk. |
| No changelog | I cannot tell which fix is new, temporary, or already reverted once. | Repeated debugging and deja-vu bug hunting. |
| No SOP/script | I repeat the same 5-10 manual steps from memory. | Inconsistent results and fragile handoffs. |
| No ADR note | Old architectural decisions look random later. | Bad reversals and unnecessary rewrites. |
| No user context checklist | The app solves a fuzzy problem for a fuzzy audience. | Nice demo, weak product direction. |
I do still believe local context matters when the product truly targets one market. But the reusable lesson is bigger and simpler: every project needs a user context checklist, and only some projects need a country-specific extension. [R1]
How I Would Explain This to Another AI Agent in One Minute
If another AI agent joins the repo tomorrow, my ideal handoff is not a 2,000-word prompt. It is something like this:
Project goal: Help users complete X safely and quickly.
Read README.md for setup.
Read AGENTS.md before touching code.
Read CHANGELOG.md for the last notable decisions and fixes.
Use SOP.py for repeated tasks instead of improvising commands.
If you change architecture, add a short ADR note.
If you change user-facing behavior, update the user context checklist and changelog.That is it. Short. Portable. Reusable. Beginner-friendly. And much closer to how these tools are actually evolving than the old fantasy that one magical prompt will keep the project coherent forever. [R2][R4][R5][R6]
PlantUML Diagram: Keep Context Fresh After Every Change
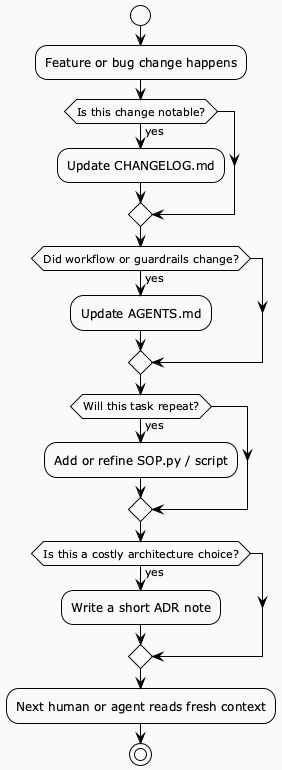
Honest Limits: Documentation Can Also Become a Trap
I should say this clearly because otherwise this post becomes hypocritical: more documentation is not automatically better. A repo with twelve stale context files is worse than a repo with three living ones. Personal experience only, small sample size, but I have already made this mistake.
So my current rule is simple: if the project will last more than a weekend, or if another human or agent will touch it, create the minimal context stack. If the project is a throwaway experiment, keep it light. The goal is not ceremony. The goal is continuity.
- Write the minimum shared truth in
AGENTS.md. - Record notable project memory in
CHANGELOG.md. - Script repeated work in
SOP.pyor a small helper script. - Only add ADR notes for decisions that are costly to reverse.
That sequence is also why I no longer think Part 2 should be framed as “my Vietnamese framework.” The better title in my own head now is something like: build a project memory system that survives the next agent.
FAQ
Do I need all four pieces on day one?
No. For a tiny experiment, start with README.md and AGENTS.md. Add CHANGELOG.md once the project has real change history. Add SOP.py when repetition appears. Add ADRs only for big decisions.
Does SOP have to be Python?
Not at all. It can be Bash, Make, Node, PowerShell, or whatever fits the environment. I use SOP.py as a mental label for “repeatable operational logic,” not as a religion.
Is this only useful for AI agents?
No. Humans benefit too. The funny part is that AI exposed the weakness faster. When a new agent fails in five minutes, you immediately notice the project has no memory. Human teammates suffer from the same problem, just more politely.
Conclusion: Context Engineering Is Really About Durable Memory
Part 1 helped me see the difference between ad-hoc generation and systematic engineering. Part 2, after this correction, lands on a simpler point: context engineering is not only about planning before code. It is also about preserving enough project memory so the next round of work does not start from zero. [R1][R2][R4][R5][R7][R8]
So yes, keep your prompts. Keep your experiments. Keep your intuition. But if you want the work to survive beyond one lucky session, teach the repo how to speak for itself. AGENTS.md for guidance. CHANGELOG.md for memory. SOP.py for repetition. ADR notes for important decisions. That is the framework I actually trust right now.
Mong được nghe góp ý của bạn. If you already have your own version of this stack, I would genuinely love to compare notes. What is in your repo that helps the next human or agent recover context fast?
TÓM TẮT NHANH
My current stack: README.md + AGENTS.md + CHANGELOG.md + SOP.py/scripts + short ADR notes when needed.
Why it matters: modern agent tools increasingly load repo instructions and benefit from shared project context, but they still fail when memory is missing or stale. [R2][R4][R5][R6]
Better checklist: use a generic user context checklist first, then add local or cultural extensions only when the product really needs them.
Honest limit: too much documentation becomes another form of mess. Keep the stack small and alive.
Read Part 1: Context Engineering vs Vibe Coding: A Business Person’s Technical Discovery (Part 1 of 2) for the first half of this learning journey. [R1]
References
[R1] Le Cuong. (2025, November 9). Context engineering vs vibe coding: A business person’s technical discovery (Part 1 of 2). https://pmlecuong.com/context-engineering-vs-vibe-coding-a-business-persons-technical-discovery-part-1-of-2/
[R2] OpenAI. (2026, January 23). Unrolling the Codex agent loop. https://openai.com/index/unrolling-the-codex-agent-loop/
[R3] OpenAI. (2025, June 3). How OpenAI uses Codex to power its own engineering. https://openai.com/index/how-openai-uses-codex-to-power-its-own-engineering/
[R4] Anthropic. (n.d.). How Claude remembers your project. https://code.claude.com/docs/en/memory
[R5] Kiro. (2025, November 3). Remote MCP, global steering, sequential hooks, and simplified trusted commands. https://kiro.dev/changelog/ide/0-5/
[R6] Kiro. (2025). Automate your development workflow with Kiro’s AI agent hooks. https://kiro.dev/blog/automate-your-development-workflow-with-agent-hooks/
[R7] Keep a Changelog. (n.d.). Keep a Changelog. https://keepachangelog.com/en/1.1.0/
[R8] Google Cloud. (2024, August 16). Architecture decision records overview. https://cloud.google.com/architecture/architecture-decision-records
[R9] agentsmd. (2025). AGENTS.md: A simple, open format for guiding coding agents. https://github.com/agentsmd/agents.md
[R10] OpenAI. (2025). Agent Skills. https://github.com/openai/skills
[R11] Park, J., Cho, J., & Ahn, S. (2025). MrSteve: Instruction-following agents in Minecraft with what-where-when memory. ICLR 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/2af7168a1f19e0ae61134f89eb238e57-Paper-Conference.pdf
[R12] Kang, J., Ji, M., Zhao, Z., & Bai, T. (2025). Memory OS of AI Agent. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. https://aclanthology.org/2025.emnlp-main.1318/
[R13] MemTensor. (2025-2026). MemOS: A memory OS for AI systems. GitHub repository. https://github.com/MemTensor/MemOS
[R14] agentscope-ai. (2025). ReMe: Memory management kit for agents. GitHub repository. https://github.com/agentscope-ai/ReMe
[R15] OpenClaw. (2026). Memory. https://docs.openclaw.ai/concepts/memory
[R16] OpenClaw. (2026). Skills. https://docs.openclaw.ai/tools/skills
[R17] OpenClaw. (2026). Hooks. https://docs.openclaw.ai/automation/hooks
Related reading
Read the relevant post here:
- Context Engineering vs Vibe Coding: A Business Person’s Technical Discovery (Part 1 of 2)
- Intent First, Prompts Second: A Practical Model for AI Projects
- Agents Are Just Tools in a Loop—and That’s Why They Work
Image Disclosure
Some images used in this post were created with AI. They may appear realistic, but they do not depict real scenes or real photographs unless explicitly stated otherwise. When a realistic image of me is an actual photograph, the caption will clearly note that it is a real image.


Der Begriff bleibt hängen, ngl.